新しいサイトを追加¶
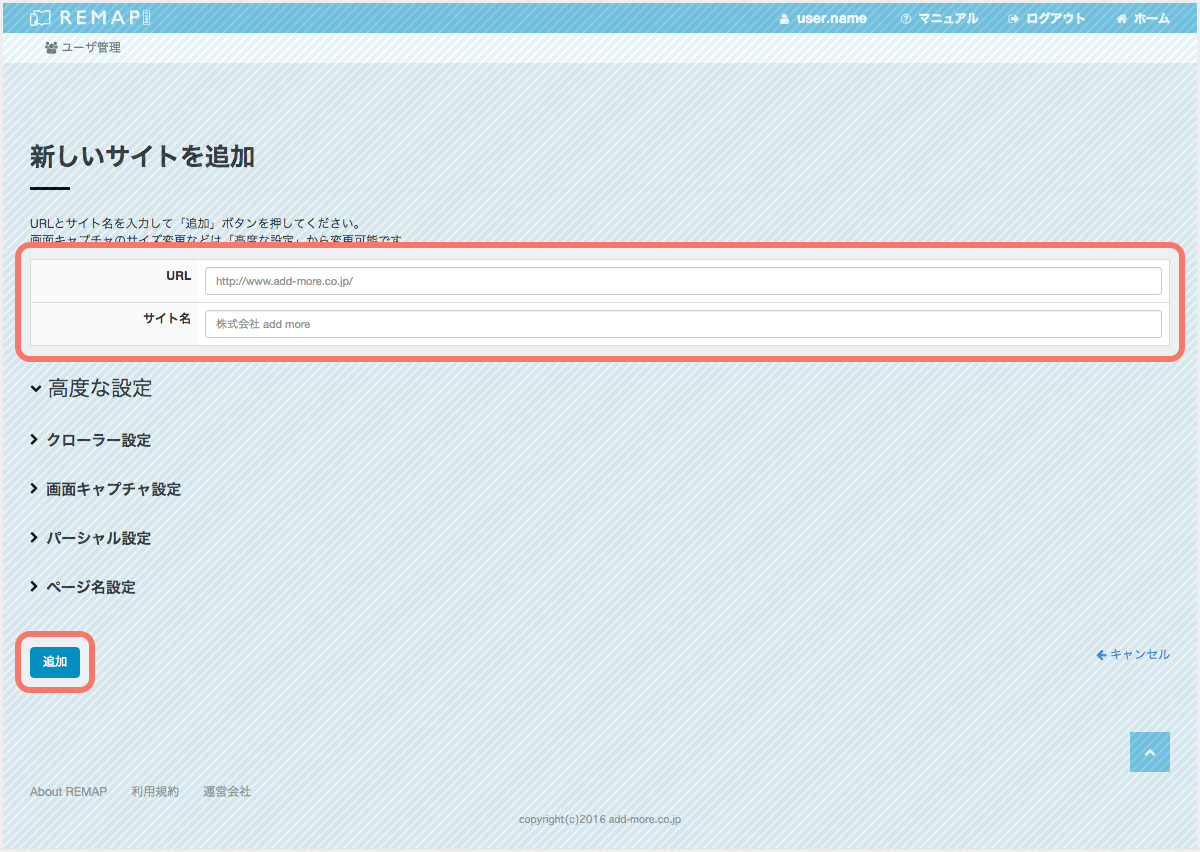
URL¶
http://username:password@example.com/ )サイト名¶
高度な設定¶
サイト解析にあたっての高度な設定を変更します。
クローラー設定¶
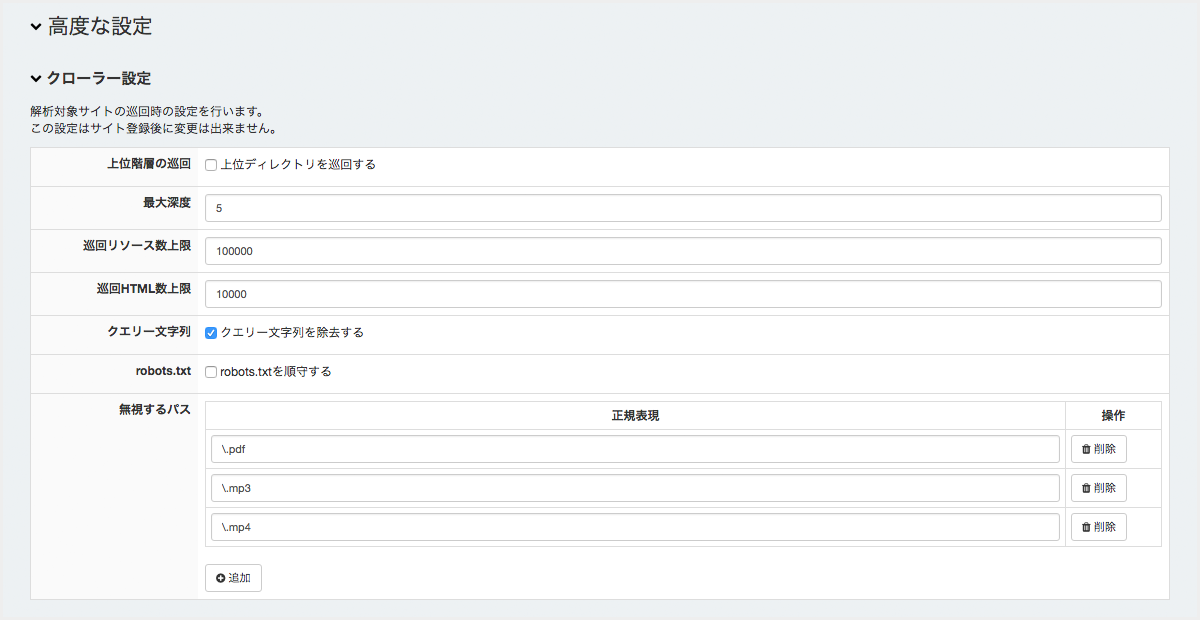
上位階層の巡回¶
http://example.com/foo/bar/ のようにサブディレクトリを含むURLが指定された場合、デフォルトでは上位ディレクトリ( http://example.com/ や http://example.com/foo/ )は巡回しません。
もし上位階層も巡回する場合は、この項目にチェックを入れてください。
最大深度¶
巡回を開始したページからの最大到達数を指定します。 到達に必要な最短の画面遷移数がこれを超えるページは巡回対象から除外されます。
巡回リソース数上限¶
HTML、画像、PDFなど種別にかかわらず、ひとつのURLを1とカウントした場合の巡回上限です。
これを超えた場合、サイト全体を巡回出来ていない状態でも巡回を完了し、ステータスが 巡回完了(上限到達) となります。
指定できる上限は契約プランによって異なります。
巡回HTML数上限¶
HTML( Content-Type に html が含まれる)を1とカウントした場合の巡回上限です。
これを超えた場合、サイト全体を巡回出来ていない状態でも巡回を完了し、ステータスが 巡回完了(上限到達) となります。
指定できる上限は契約プランによって異なります。
クエリー文字列¶
デフォルトでは、 http://www.example.com/index.php?uid=xxxx のようなURLは http://www.example.com/index.php として巡回します。
? 以降のパラメータを保持したまま巡回する必要があれば、この項目のチェックを外してください。
robots.txt¶
この項目をチェックすると /robots.txt の内容を解析し巡回禁止定義されているコンテンツはクロールしないようになります。
巡回を許可するドメイン¶
ドメインが変わるリンク先や画像の読み込みはクロール対象外となりますが、「巡回を許可するドメイン」に定義されたドメインであればクロールの対象となります。
User Agent¶
クローラの User Agent を指定します。 初期状態ではREMAPにアクセスしているブラウザのUser Agentが入力されています。
無視するパス¶
巡回時に無視するURLを定義します。 正規表現を用いて定義し、URLに部分一致する場合はスキップしデータベースへの登録を行いません。
画面キャプチャ設定¶
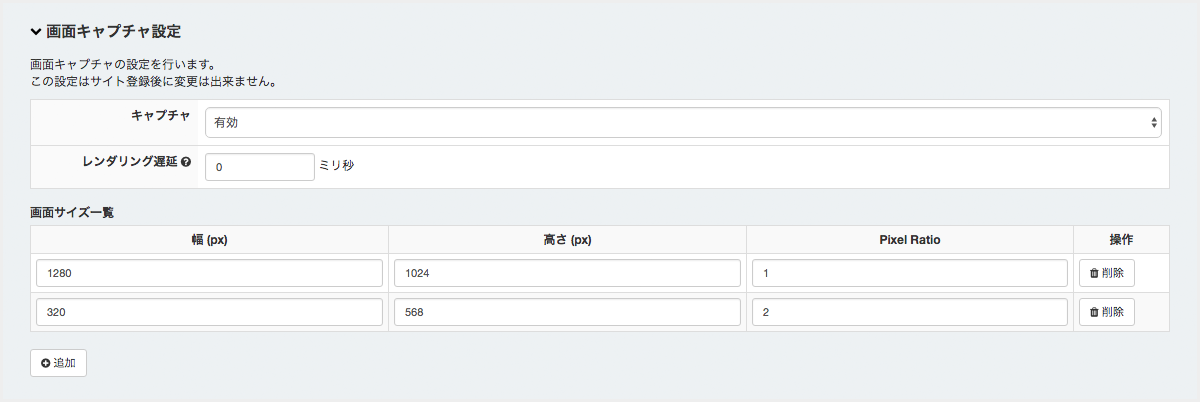
キャプチャ¶
レンダリング遅延¶
ブラウザレンダリングから画面キャプチャ作成までの待ち時間を設定します。 フェードインで画面表示するサイト等に有効です。
画面サイズ一覧¶
生成したい画面キャプチャを複数登録出来ます。
幅: 320px, Pixcel Ratio: 2 で登録された場合、幅640pxとして認識されるため @media (max-width: 320px) の条件には一致しません。画面サイズ設定例¶
| 用途 | 幅 (px) | 高さ (px) | Pixel Ratio |
|---|---|---|---|
| PC | 1280 | 1024 | 1 |
| iPhone 4 | 320 | 480 | 2 |
| iPhone 5 | 320 | 568 | 2 |
| iPhone 6 | 375 | 667 | 2 |
| iPad | 768 | 1024 | 1 |
パーシャル設定¶
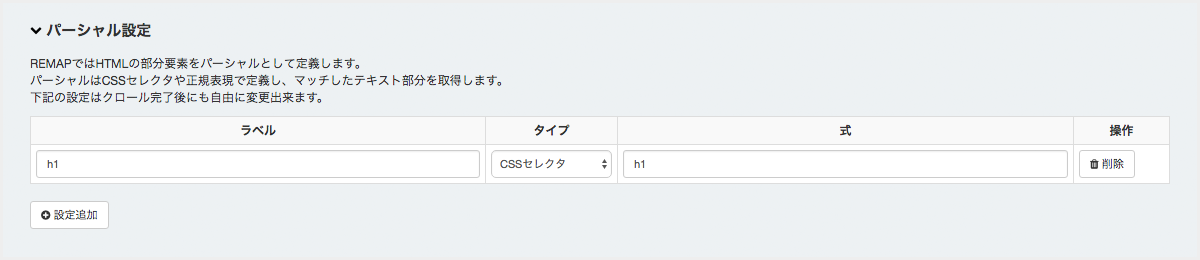
タイプ¶
CSSセレクタ か 正規表現 を選択します。
式¶
上記のタイプに応じた式を記述します。
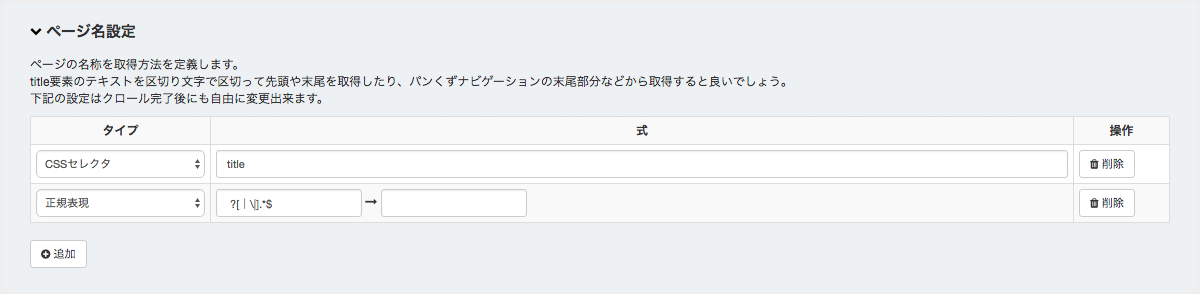
ページ名設定¶
タイプ¶
CSSセレクタ か 正規表現 を選択します。
式¶
上記のタイプに応じた式を記述します。
設定例¶
初期設定では下記のように定義されています。
| タイプ | 式 |
|---|---|
| CSSセレクタ | title |
| 正規表現 | ?[|\|].*$ → (空) |
この場合、title要素のテキストノードを取得し、パイプ区切り( | や | )で区切られた文字の先頭部分を取得することを意味します。
ページ名 | カテゴリ2 | カテゴリ1 | サイト名称 というtitleがあれば、 ページ名 の部分のみが抽出されます。